完善资料让更多小伙伴认识你,还能领取20积分哦, 立即完善>
3天内不再提示

|
有一段时间没有参加电子发烧友的开发板评测了,主要是不想总是重复以往做过的东西,希望在评测中想学点新东西突破一下自己。这次感谢电子发烧友开云(中国)官方和正点原子给的评测机会,希望充分利用i.MX93开发板实现语音智能识别功能。 项目计划1)根据文档,学习i.MX的AI开发环境和相关的程序框架。 开箱体验正点原子的产品一直以做工细致、资料丰富著名。此次开箱后立刻就喜欢上了它的板子,真是漂亮,而且接口丰富,非常时候新手入门。
音频播放测试此次的主要功能是需要通过语音实现的,所以先测试了其语音功能。
系统加电后,使用MobaXterm登录系统。开发板出厂系统里有音频配置和测试文件,按照如下指令执行音频测试脚本。 第一次运行该脚本时,会打印音频设备初始化相关操作,后续执行此脚本时不再打印初始化相关信息。按 Ctrl+c 组合键可以退出脚本。 初始化完音频设备后,输入数字 2 并确认即可播放音频测试,播放信息如下。 期间板载扬声器会播放音频,声音响亮。 录音测试还是运行刚才的脚本,初始化完音频设备后,输入数字 1 确认后,下一步选择麦克风测试项目,如果是使用带麦克风的耳机接在开发板 PHONE 接口则使用 1. 耳机麦克风;如果是没接耳机,直接使用开发板自带的板载麦克风 MIC,则使用 2. 板载麦克风。笔者使用的是开发板自带的板载麦克风MIC,这里选择第二项。选择好对应的麦克风配置后,脚本会自动进行录音,请靠近麦克风进行录音测试。录音完成后会在当前目录下生成 record.wav 文件,此文件就是笔者刚刚录音生成的音频文件。脚本在录音后会自动播放所录音频。感觉板载麦克风的噪音有点大,所以对音质要求苛刻的还是接耳机麦克风比较好。 基本测试先进行到这里,后续将进行编程测试。 |
 1363
1894
920
1705
9441
1369
1882
1067
1173
903
1363
1894
920
1705
9441
1369
1882
1067
1173
903
|
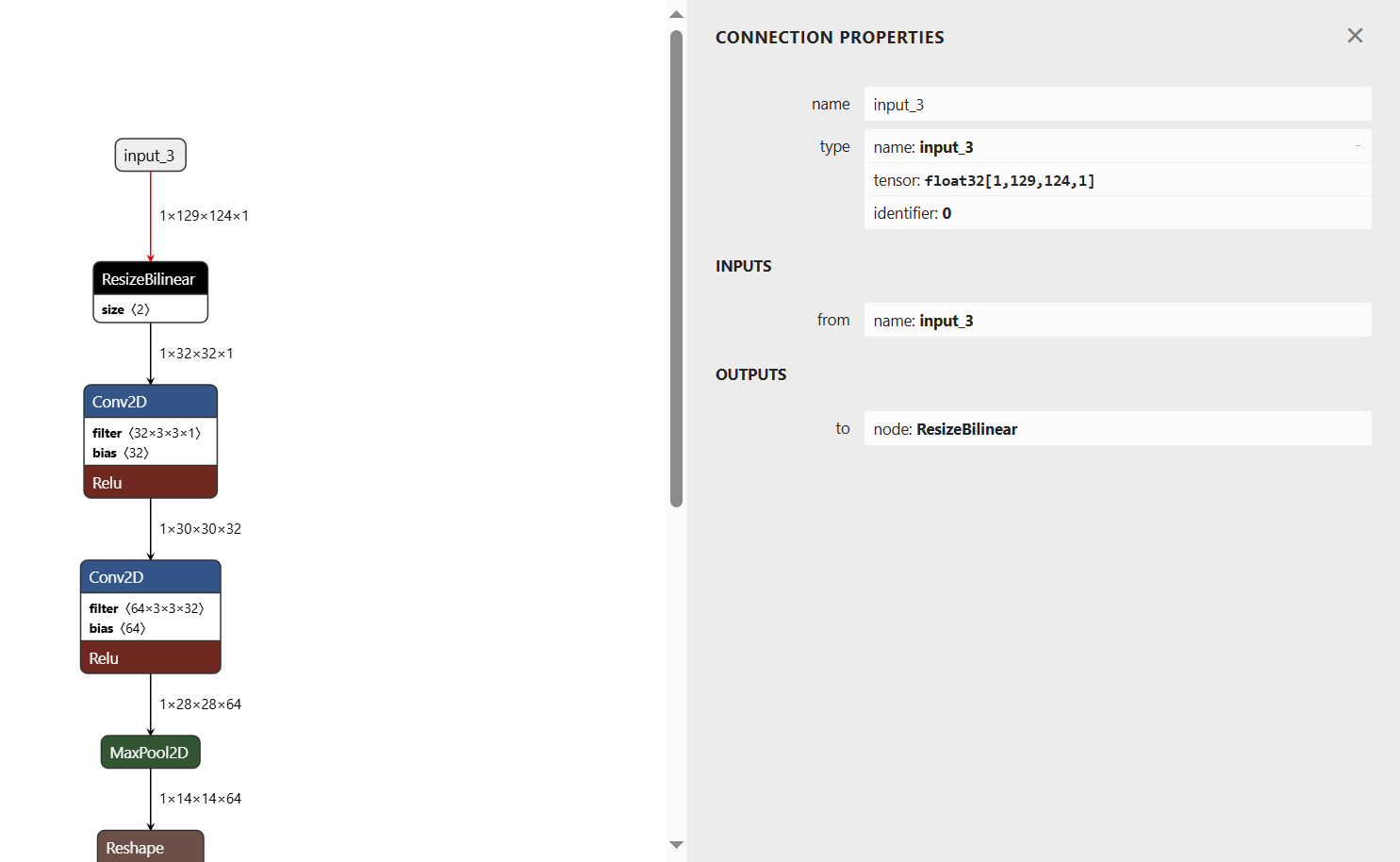
这次的主要目标就是学习NXP的AI程序开发。首先阅读了《05【正点原子】ATK-DLIMX93嵌入式AI开发手册V1.0》文档,这个文档写得很清楚,不过我建议大家读一下原厂文档《i.MX Machine Learning User's Guide》,里面有些技术细节更清楚。下面就介绍一下自己对I.MX 93平台的测试。 i.MX 93支持在Cortex-A上进行CPU推理,也支持为 Arm 自研的 Ethos-U65(NPU)上进行推理。当然后者的推理速度比前者快很多。I.MX 93对不同推理的支持是通过选择委托(Delegate)来实现的。如果选择XNNPACK就是CPU推理,而使用Ethos-U委托就是采用NPU推理。NXP在其他硬件平台上还提供了更多的推理选项,这里就不讨论了。 我测试了厂商提供的图像分类程序,它在开发板的/usr/bin/eiq-examples-git/image_classification目录中。要运行这个程序,首先需要下载模型文件。/usr/bin/eiq-examples-git/download_models.py 这个脚本是用来下载模型的,不过这个脚本要访问谷歌网盘,不方便的朋友可以从正点原子的网盘下载所需要的文件。 安装好模型文件后,如果运行python3 label_image.py就执行的是CPU推理,需要63.815ms。 如果想使用NPU推理,就需要在命令行使用-d制定推理所需要的库文件: 正点原子的文档说要使用NPU推理,需要用开发板上的vela 工具将tflite模型编译成可以使 NPU 进行推理的 vela 模型,而且模型只支持8位或16位量化。 使用NPU后,推理时间减少到4ms。 |
|
今天测试的内容是进行简单的音频分类。我们要想进行语音控制,就需要构建和训练一个基本的自动语音识别 (ASR) 模型来识别不同的单词。如果想了解这方面的知识可以参考TensorFlow的官方文档:简单的音频识别:识别关键词 | TensorFlow Core。 预训练模型来自Simple Audio Recognition on a Raspberry Pi using Machine Learning (I2S, TensorFlow Lite) - Electronut Labs,我在它提供的代码基础上进行了修改。NXP官方的Model Zoo也提供了类似的代码,不过它需要TensorFlow类,而开发板上默认提供Tflite runtime推理框架,所以我没有使用NXP的方案。 本模型使用 Speech Commands 数据集的一部分,其中包含命令的短(一秒或更短)音频片段,例如“down”、“go”、“left”、“no”、“right”、“stop”、“up”和“yes”。 数据集中的波形在时域中表示,通过计算短时傅里叶变换 (STFT) 将波形从时域信号转换为时频域信号,以将波形转换为[频谱图](频谱图_百度百科 (baidu.com)),显示频率随时间的变化,并且可以表示为二维图像。然后把频谱图图像输入您的神经网络以训练模型。 在前面提到网页中有模型训练的方法。这里采用的是已经训练好的模型。在模型推理部分,首先从wav文件中读取语音数据,如果是双声道的,只使用其中的一个声道。默认音频的采样率是16k,只提取音频中的1s数据进行测试。数据提取后,需要归一化,然后利用STFT转换为频谱图,再输入神经网络进行计算。 程序中使用了scipy库进行STFT处理,所以需要先安装scipy库,执行如下命令: 我在i.MX 93开发板上运行了测试Python程序,它可以正确识别YES和NO。其中yes.wav是我自己录制的。
现在所用的模型是浮点的,只能用于CPU推理而不能使用NPU推理。如果希望使用NPU推理,需要将模型进行转换,并修改程序进行量化处理。 |
|
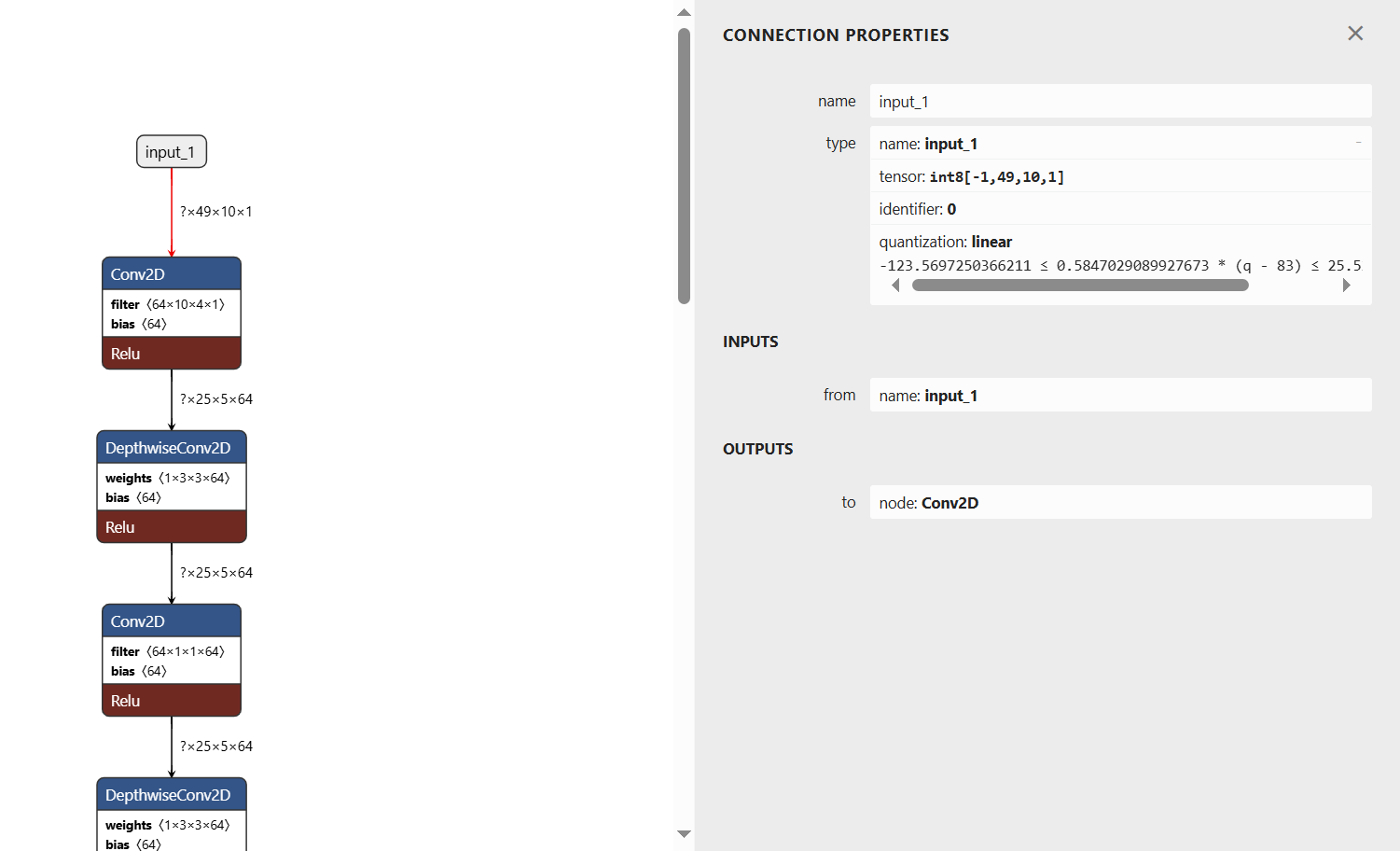
昨天提到要使模型运行的NPU上,必须先将其量化。如果对没有量化的模型使用vela工具进行转换,工具会给出警告,所生成的模型仍然是只能运行在CPU上,而无法运行在NPU上的。 这个错误信息明确指出Vela不支持 TensorFlow Lite 对特定操作的支持问题。具体来说,这个警告说明了:量化参数缺失 ,错误信息指出,涉及的输入、输出和权重张量必须具有量化参数,但在这个操作中,某些张量(如
而查看被vela支持的模型,可以看到其输入参数已经被量化,是int8类型的。 如果我们想利用i.MX 93的NPU能力就需要先对模型文件进行量化。当然如果觉得i.MX 93的CPU推理能力已经够用了,此步骤也可以省略。 |
|
接下来我就想把录音和关键词识别整合在一个程序里面。 Python中进行语音操作首先想到的是PyAudio。不过在板子上安装PyAudio遇到一点麻烦。Python仓库里面并没有现成的对应这个板子的软件包,需要在板子上编译生成软件包,而PyAudio又依赖PortAudio,而PortAudio在板子上没有移植,所以PyAudio暂时用不了,这个问题以后再想办法解决。 我采用的临时办法是修改前面提到的测试音频的shell脚本,由它录制1秒的语音,然后调用Python程序进行关键字识别,如果是YES就打开开发板上的LED灯,如果是NO就关闭开发板上的LED灯,开灯或关灯完成之后会播放相应的提示音。为了方便调试,在录音之后会自动播放录音结果,以确定录音是否正确。 完整的程序见压缩包*附件:yes-no-test.zip。核心的脚本代码如下: 从下面的视频看,基本实现了所需要的效果。原来担心板子的麦克风录音效果会影响识别,目前看问题不大。由于采用的是先录音成文件的方法,而且时间仅有1秒,所以使用时还是比较麻烦的,有的时候说话稍微慢了点就没有录制完全。这个需要后续优化一下Python的语音处理。 |
|
本帖最后由 zealsoft 于 2024-7-14 17:25 编辑 接下来就是要尝试训练中文提示词。首先要进行语料采集,这是一个比较耗费人力的事情,通常大公司会有有专人进行语料收集,我只好自己亲自做。这里参考了AliOS Things里面提供的一个录音工具,方便快速录音。对这个工具做了一点修改,原来的代码只能在Linux下运行,现在改成在Windows下也能运行。
|
|
好久没有更新了,今天再来更新一下。 我们用前面提到的录音工具录制了自己的中文语音,包括“打开”和“关闭”各100条,同时我们从谷歌的mini_speech_commands样本集里面随机挑选了100条作为"unknown”的样本,三个类别的数据个数要尽量相同,否则训练出来的结果会有倾向性。然后,开始自己的训练过程。 我所使用的是阿里云的PAI-DSW进行在线训练,平台的使用非常方便,避免了在本机上进行繁琐的设置工作。我采用的训练笔记本是TensorFlow的Simple audio recognition: Recognizing keywordssimple_audio_pi/simple_audio_train_numpy.ipynb
将脚本上传后,直接打开,就可以看到笔记本了。 笔记本的操作和其他平台差不多,就不详细介绍了。 我把准备的语音数据上传到data/speech目录下,共有3个子目录,分别是open、close和unknown。然后修改脚本中关于data_dir的设置。 然后修改了训练集、验证集和测试集的数量设置。 然后就按照笔记本里面的步骤执行就可以了。 数据量不大,训练只用了数秒就完成了。 使用一个样本进行测试,可以正确得到打开的结果。
最后可以得到tflite格式的文件,用于在开发板上的测试。 将tflite格式的文件拷贝到开发板上,并修改前面的测试程序中的模型文件路径和commands设置就可以使用中文的“打开”、“关闭”进行控制了。视频稍后将上传到B站,欢迎大家观看。 |
只有小组成员才能发言,加入小组>>
【正点原子STM32H7R3开发套件试用体验】【主贴】- 基于STM32H7R3的远程隧道气压监测终端
1371 浏览 5 评论
【正点原子STM32H7R3开发套件试用体验】SD卡、音乐播放器
1116 浏览 0 评论
【正点原子STM32H7R3开发套件试用体验】DS18B20、DHT11温湿度采集
726 浏览 0 评论
【正点原子STM32H7R3开发套件试用体验】按键、串口通信
1192 浏览 0 评论
【正点原子STM32H7R3开发套件试用体验】移植lua解释器
515 浏览 1 评论
【正点原子STM32H7R3开发套件试用体验】桌面化多传感器管理与控制
2546浏览 23评论
【正点原子STM32H7R3开发套件试用体验】4G联网工业设备控制网关
21234浏览 9评论
【正点原子i.MX93开发板试用连载体验】基于深度学习的语音本地控制
29063浏览 6评论
【正点原子STM32H7R3开发套件试用体验】【主贴】- 基于STM32H7R3的远程隧道气压监测终端
1373浏览 5评论
【正点原子STM32精英V2开发板体验】很遗憾测评未动解BUG先行-关于BOOT的问题分享
1594浏览 4评论

电子发烧友网

电子发烧友开云(中国)官方
 /6
/6 
关注我们的微信

下载发烧友APP

电子发烧友观察

版权所有 © 湖南华秋数字科技有限公司
电子发烧友 (电路图) 湘公网安备 43011202000918 号 电信与信息服务业务经营许可证:合字B2-20210191 工商网监
湘ICP备2023018690号
工商网监
湘ICP备2023018690号








 淘帖
淘帖 显身卡
显身卡